금요일, 1월 20, 2017
EzBioCloud 16S DB 관련
천종식교수님께서 CEO로 있으신 천랩에서
ezbiocloud를 개편하면서 16S db도 오픈을 해서
다운로드받아 사용할 수 있게 해주신건 이미 알고 계시죠!
다만 그 가운데 taxonomy.txt 파일에 level이 kingdom마다 상이한게 있어서
천랩에 수정요청을 드렸고 수정됐다고 합니다.
분석 자체에는 당근 문제가 없지만
추후에 결과 display할때 예외처리 같은거 해줘야 하는 수고가 있는 관계로
수정을 부탁드렸었습니다.
아마 이제 받으시는 데이터는 level 7인 데이터로 받을 수 있지 않을까 합니다. :)
목요일, 1월 19, 2017
HGAP parameter 비교 결과
우선 PacBio에서 사용되는 용어에 대해서
잘 정리된 문서가 있어 링크 합니다.
>PacBio Term<
작년 말에 PacBio SMRT portal 에서 HGAPv2와 HGAPv3비교를 해보려고 했는데 해보신분은 아시다싶이 HGAPv2의 **맞은 속도로인해 HGAPv2의 parameter 비교는 skip하고 HGAPv3를 기준으로 parameter마다 bacteria genome이 어떤 변화가 있는지 비교해보았습니다.
-그렇다고 제가 HGAPv3를 사용한다는것은 아니라는 점! ;)
HGAPv3은 기존의 다른 de novo assembly 프로그램과 유사하게 Filtering/ Assembly/ Mapping/ Consensus 단계를 거쳐 진행합니다.
대게 de novo assembly 메뉴얼 작업을 하신 분들의 경우 filtering/trimming하고 assembly 무한 반복? 하고 mapping해서 insert size대로 mapping이 되는지 확인을 해보셨을 겁니다. ㅎㅎ
근데 PacBio Portal에서 스스로 잘 해줍니다. @.@
다음은 step마다 있는 parameter와 값들을 한번 정리 해봤습니다.
위의 옵션들 중에서 제가 직접 조정해본 parameter들은 Filtering단계인 Min Subread Length, Min Polymerase Read Quality, Min Polymerase Read Length, Assembly단계중 AssebleUnitig단계인 Genome Size, Target Coverage, 그리고 같은 Assembly단계인 PreAssemblerHGA단계의 Min. Seed Read Length정도를 고려해봤습니다. 건드린 옵션 이름보시면 매뉴얼 de novo assembly해보신 분들이라면 예상 가능하시리라 봅니다.
-음.. 가끔 이런 거 보다 더 잘 정리해서 논문으로 출판되는 경우가 있긴하지만....
그리고 추가적으로 더 손대면 결과가 좋아질 수 있을만한 옵션들이 있겠지만 시간관계상 (제가 주구장창 이것만 돌릴 수 있는 처지는 아닌지라... 모 여러 조건의 샘플과 무한한 서버를 제공해주신다면 테스트는 해드릴 수 있습니다. ;) )
여튼 결과부터 말씀드리자면 조건 변경(aka 최적화)해서 결과 얻으면 좀더 좋아질거 같죠?
시간낭비하지 마셈 되겠습니다. >_<
너님 나랑 장난하냐? 너 이자식 지금 결과보여주기 귀찮아서(이건 부정 못하겠네요ㅋ) 주작질 하는거지? 하실 수도 있는데 제가 테스트한 기준이 보통 bacteria genome을 진행하는데 사용되는 1 Cell 이라서 그런 탓도 있겠지만 알고있던 정보와 실제 나온결과와 10%이상 차이 안 나면 옵션 암만 최적화 해봤자 그 나물의 그 밥입니다.
그리고 옵션마다 값을 조절하면 그에 따라 그 다음 스텝의 input이 바뀌어 영향을 받지만 한정된 데이터에서 옵션값 조절해서 데이터의 결과가 다이내믹하게 바뀐다면 그건 최적화를 잘한 것이 아니라 시퀀싱데이터가 이상할거라는 느낌적인 느낌이 드시죠?
Filtering단계에서 read길이 올리고, 줄이고, 조금 떨어지는 데이터를 확보한다는 계획으로 read quality를 낮추더라도 어차피 서로 계속 영향을 줘서 default parameter로 생성된 데이터와 큰 차이 안 납니다.
결론: 1 contig 안 나오고 circluar형성 안되는 애들은 parameter 최적화 해봤자 안됩니다. 스트레스 받지말고 추가 시퀀싱하세요.
샘플 좋고 시퀀싱 잘되면 분석툴이 개 이상하지 않으면 reasonable한 결과 나옵니다. :)
default 의외로 성능 괜찮습니다. 내가 연구하는 건 나처럼 변태스러운 녀석이야! 하지 않는 이상 default쓰시면 평타는 칩니다.
ps. 믿거나 말거나 조건 변경하면서 20번정도 테스트 해봤습니다. PacBio에서 제시하는 것 중에 추천하는 Genome Size 옵션이 영향을 많이 줄 수 있습니다. Genome Size를 기준으로 데이터를 정리하기 때문에 그런 것 같습니다. 그리고 Target Coverage는 bacteria의 경우 1 cell만 해도 대중 100x가 나오는데 target coverage (15-30) 조절해봤자 의미 없는 것 같습니다. bacteria말고 다른 종들은 의미가 있을지도...
잘 정리된 문서가 있어 링크 합니다.
>PacBio Term<
작년 말에 PacBio SMRT portal 에서 HGAPv2와 HGAPv3비교를 해보려고 했는데 해보신분은 아시다싶이 HGAPv2의 **맞은 속도로인해 HGAPv2의 parameter 비교는 skip하고 HGAPv3를 기준으로 parameter마다 bacteria genome이 어떤 변화가 있는지 비교해보았습니다.
-그렇다고 제가 HGAPv3를 사용한다는것은 아니라는 점! ;)
HGAPv3은 기존의 다른 de novo assembly 프로그램과 유사하게 Filtering/ Assembly/ Mapping/ Consensus 단계를 거쳐 진행합니다.
대게 de novo assembly 메뉴얼 작업을 하신 분들의 경우 filtering/trimming하고 assembly 무한 반복? 하고 mapping해서 insert size대로 mapping이 되는지 확인을 해보셨을 겁니다. ㅎㅎ
근데 PacBio Portal에서 스스로 잘 해줍니다. @.@
다음은 step마다 있는 parameter와 값들을 한번 정리 해봤습니다.
| Step | Protocol | Parameter | Value |
| Filtering | PreAssemblerSFilter.1.xml | Min. Subread Length | 500 |
| Min. Polymerase Read Quality | 0.8 | ||
| Min. Polymerase Read Length | 100 | ||
| Control Filtering | KeepControlReads.1.xml | None | None |
| Assembly | AssembleUnitig.1.xml | Genome Size | 5000000 |
| Target Coverage | 25 | ||
| Overlapper Error Rate | 0.06 | ||
| Overlapper Min Length | 40 | ||
| Overlapper K-Mer | 14 | ||
| PreAssemblerHGA.3.xml | Min. Seed Read Length | 6000 | |
| Num. of Seed Read Chunks | 6 | ||
| Alignment Candidates Per Chunk | 10 | ||
| Total Alignment Candidates | 24 | ||
| BLASR Options | -noSplitSubreads -minReadLength 200 -maxScore -1000 -maxLCPLength 16 | ||
| Min Coverage For Correction | 6 | ||
| Mapping | BLASR_Resequencing.1.xml | Max. Divergence | 30 |
| Min. Anchor Size | 12 | ||
| Consensus | AssemblyPolishing.1.xml | None | None |
위의 옵션들 중에서 제가 직접 조정해본 parameter들은 Filtering단계인 Min Subread Length, Min Polymerase Read Quality, Min Polymerase Read Length, Assembly단계중 AssebleUnitig단계인 Genome Size, Target Coverage, 그리고 같은 Assembly단계인 PreAssemblerHGA단계의 Min. Seed Read Length정도를 고려해봤습니다. 건드린 옵션 이름보시면 매뉴얼 de novo assembly해보신 분들이라면 예상 가능하시리라 봅니다.
-음.. 가끔 이런 거 보다 더 잘 정리해서 논문으로 출판되는 경우가 있긴하지만....
그리고 추가적으로 더 손대면 결과가 좋아질 수 있을만한 옵션들이 있겠지만 시간관계상 (제가 주구장창 이것만 돌릴 수 있는 처지는 아닌지라... 모 여러 조건의 샘플과 무한한 서버를 제공해주신다면 테스트는 해드릴 수 있습니다. ;) )
여튼 결과부터 말씀드리자면 조건 변경(aka 최적화)해서 결과 얻으면 좀더 좋아질거 같죠?
시간낭비하지 마셈 되겠습니다. >_<
너님 나랑 장난하냐? 너 이자식 지금 결과보여주기 귀찮아서(
그리고 옵션마다 값을 조절하면 그에 따라 그 다음 스텝의 input이 바뀌어 영향을 받지만 한정된 데이터에서 옵션값 조절해서 데이터의 결과가 다이내믹하게 바뀐다면 그건 최적화를 잘한 것이 아니라 시퀀싱데이터가 이상할거라는 느낌적인 느낌이 드시죠?
Filtering단계에서 read길이 올리고, 줄이고, 조금 떨어지는 데이터를 확보한다는 계획으로 read quality를 낮추더라도 어차피 서로 계속 영향을 줘서 default parameter로 생성된 데이터와 큰 차이 안 납니다.
결론: 1 contig 안 나오고 circluar형성 안되는 애들은 parameter 최적화 해봤자 안됩니다. 스트레스 받지말고 추가 시퀀싱하세요.
샘플 좋고 시퀀싱 잘되면 분석툴이 개 이상하지 않으면 reasonable한 결과 나옵니다. :)
default 의외로 성능 괜찮습니다. 내가 연구하는 건 나처럼 변태스러운 녀석이야! 하지 않는 이상 default쓰시면 평타는 칩니다.
ps. 믿거나 말거나 조건 변경하면서 20번정도 테스트 해봤습니다. PacBio에서 제시하는 것 중에 추천하는 Genome Size 옵션이 영향을 많이 줄 수 있습니다. Genome Size를 기준으로 데이터를 정리하기 때문에 그런 것 같습니다. 그리고 Target Coverage는 bacteria의 경우 1 cell만 해도 대중 100x가 나오는데 target coverage (15-30) 조절해봤자 의미 없는 것 같습니다. bacteria말고 다른 종들은 의미가 있을지도...
수요일, 1월 18, 2017
논문 컨설팅 관련한 짧지 않은 글
본 글은 지식펜에 대한 제 페북타임라인에 댓글로 올라온 박원수대표님의 글에 대한
제 생각을 적은 것입니다.
다음 글은 지식펜 박원수대표님께서 올리신 글입니다.
--
현재 국내 대학원 시스템이 인류 역사상 현존하는 유일무이하고 가장 선진화된 무결점의 시스템은 아니나 국내에서 당분간은 이 시스템이 굴러갈 것이라고 생각되어 현재 대학과 대학원 시스템이라는 테두리안에서 글을 쓰고자 합니다. 그리고 제가 일반대학원을 다녔던터라 특수대학원의 시스템을 정확히 모르는 관계로 일반대학원을 기준으로 말을 하려고 합니다.
※ 본 글을 쓰기전에 박원수대표님께서 작성하신 글 중에 확인하고 갈 부분들이 있어서 먼저 집고 넘어가고자 합니다. 그리고 나오는 내용은 전적으로 저의 사견이니 오해없으시길 바랍니다.
[연구자들이 선행연구들을 이해하기 어려운 이유 중에 하나는 대학원 과정에서 체계적으로 훈련을 받지 못하였기 때문으로 판단합니다.]
선행연구를 이해하기 어려운 이유는 두가지입니다. 흥미 또는 필요가 없거나 공부를 안했거나입니다. 본인이 필요한 연구임에도 이해하기 어렵다고 정체되어 있다는 것을 대학원 과정에서 체계적으로 훈련받지 못했다고 둘러대는 것은 좀 안타깝다고 생각됩니다. 어려운 연구들이 있을 수는 있습니다. 그렇다고 가만히 있지 않습니다. 스스로 돌파구를 찾아냅니다.
[직장인들은 시간 부족으로 인하여 더 불리한 조건에 내몰려 있습니다.]
대학원을 진학할 때는 모두들 나름의 이유와 목적을 가지고 시작하게 됩니다. 직장인이기에 시간이 부족하지만 그것이 불리한 조건이라고 말하기는 어렵습니다. 대학을 졸업하고 대학원에 진학한 학생들은 최상의 조건에서 생활하고 퇴직하고 대학원에 진학하는 분들께는 불리한 면이 없을까요? 직장인이라는 것으로 시간이 부족하고 불리한 조건이라고 말씀하시는것에는 어폐가 있다고 보여집니다.
[서울시내 모 대학원 졸업생들의 평균 8%정도만 겨우 학위를 받는 것으로 파악되고 있습니다.]
특수대학원의 경우 졸업과 학위가 동일한지 아닌지 모르겠으나 일반대학원의 경우 졸업을 하면 학위를 수여받는것으로 알고 있는데 졸업생들의 극히 일부가 학위를 받는 것에 대한 내용은 확인 부탁드립니다.
-본글-
학위를 마무리하는 작업에는 거무튀튀한 라면 받침에 최적화된 하드커버 논문이지만 그 논문을 작성하기 위해서 소위 삽질들을 무수히 하게됩니다.
이 삽질이 보는이에 따라서 무의미하고 시간낭비라고 볼 수 있지만 그 삽질속에서 시행착오를 거치면서 성장 할 수 있는 기반을 다지고 생각하는 힘을 가지게 된다고 생각합니다.
이런 무의하다고하는 과정을 이미 경험했으며 연구방법과 논문 지도에 특화되고 전문화된 분들께서 컨설팅을 해서 이런 소모성 시간을 단축해주겠노라 그리고 글로벌한 수준의 논문을 작성할 수 있게끔 지도해주겠다라고 '지식펜'이라는 컨설팅 기관이 출현했는데 과연 그 무의미하다고 생각되는 단계와 시간을 단축하는 것이 정말 학위하는 과정에 필요한 것인지 혹은 학위 이후에 연구를 해나가는데 있어서 맞는 것인가 하는 것은 다른 이야기라고 봅니다.
이런 논문/연구 컨설팅업체가 필요없다 필요하다는 제가 말할 위치도 아니고 있어서는 안되는 악으로도 보지 않습니다. 시장이 있는데 사업을 하지 않는 것은 말이 안되죠. 다만 이것이 진짜 업체에서 얘기하는 긍정적인 측면이 더 큰지는 잘 모르겠습니다. (컨설팅 업체가 있음으로써 연구 부정/논문 대필이 줄어드는 효과를 보일 것인지는 잘 모르겠습니다.)
그래서 '지식펜' 광고에 실소가 절로 나왔습니다.
안타깝게 주위에 지식펜에 컨설팅을 받아 본 지인이 없는 관계로 무조건적인 비판과 비난은 적절치 않다고 보지만 학위 논문을 작성하기까지 그간 겪었던 것은 학위를 받는 것에 것에 끝나지 않고 스스로 생각해서 연구를 하기 위한 훈련을 하는 것도 포함된다고 생각해서 지식펜이라는 컨설팅에 부정적인 생각이 큰 것 같습니다.
스스로 연구를 진행함에 있어서 습관은 무섭게 작용할 것 입니다. 학위를 하면서 무엇인가 큰 바위로 인해 길이 막혔을 때 손쉽게 해결해 주는 요술 지팡이를 언제든지 쓸 수 있다고 한다면 요술지팡이만을 의지해서 이것이 왜 문제가 있는지 왜 잘못된 방향인지 장고할 시간을 빼앗긴다면 비록 당장에는 시간을 단축했다, 내 열정을 다른 더 좋은 곳에 사용 할 수 있을 것이라 느껴지겠지만 결국 점점 더 의존하게 되는 악순환이 될 수도 있습니다.
적재적소에 지식펜과 같은 컨설팅을 활용한다면 이상적인 교육 생태계가 만들어질수도 있겠지만 과연 이런 적재적소에 기여해서 선순환적인 결과를 만들어낼지 현재의 교육 시스템을 보면 어렵다고 생각됩니다. (이 부분은 교육 컨설팅업체들만의 문제보다는 교육시스템의 문제긴 합니다.)
지금까지 일반대학원을 기준으로 글을 작성하였는데 특수대학원이 기준이 된다면 지식펜과 같은 컨설팅업체가 필요할수도 있겠다 생각이 들었습니다. 특수대학원의 경우 일반대학원과는 달리로 현장 실무를 익힌 분들을 위한 재교육의 목적이 크기에 현장에서 사용되는 보고서나 제안서등에는 탁월할지 모르나 학문을 위한 논문이라는 양식에 대해서는 어려워 할 수도 있고, 비록 위에서는 제가 직장인이라고 해서 불리한 조건이 아니라는 얘기를 했으나 이는 일반대학원의 경우로, 특수대학원을 기준으로는 좀 달라질 수 있다고 보기에 한편으로는 이들을 위해서라면 컨설팅 업체의 존재가 필요 할 수도 있을것 같았습니다.
그러나 위에서 박원수 대표님께서 언급하신 최근 대두되는 고위공무원들의 학위 논문 문제들에 대해서는 업체측의 무던한 노력이 필요할 것 이라고 생각됩니다.
아래는 최근 학위논문으로 문제가 됐던 분들 중 몇 분의 내용을 확인해 본 것입니다.
#이름 (나이) 문제가된 학위논문/ 논문이 문제가된 시점/ 논문 작성 당시 직위 (순서는 나이순)
최흥집 (1951) 1993년 강원대 경영대학원 석사학위 / 2014년 강원도지사출마 /국제관광박람회조직위원회 총괄기획부 부장
박승주 (1952) 2004년 동국대 행정학대학원 박사학위 / 2016년 안전처장관 내정자 / 확인못했음
서남수 (1952) 1995년 동국대 교육대학원 박사학위 / 2014년 교육부장관 /교육인적자원부 기획관리실 교육정책기획관
윤성규 (1956) 2006년 한양대 산업경영대학원 석사학위/ 2013년 환경부장관 후보자 / 제14대 국립환경과학원 원장
이철성 (1958) 2000년 연세대 행정대학원 석사학휘 / 2016년 경찰청장 내정자/ 공무원
조경규 (1959) 1991년 서울대 행정대학원 석사학위 / 2016년 환경장관 내정자 / 29회 행정고시, 공무원
제 생각을 적은 것입니다.
다음 글은 지식펜 박원수대표님께서 올리신 글입니다.
--
안녕하세요?--
대학원생들이 스스로 논문주제를 발굴하기 위해서는 연구자와 지도교수님의 관심 분야 논문을 체계적으로 이해하는 능력이 우선되어야 합니다. 그러나 선행연구들이 양적연구와 질적연구들이 혼재되어 있어서 연구방법을 이해하지 않고는 논문을 읽고 자기 것으로 소화하기 어렵습니다.
이로 인해 많은 수의 대학원 수료자들이 '연구분야'만 선정한 뒤 선행논문들을 찾아놓고 읽어 나가지 못하고 있습니다. 학문의 세계로 진입하지 못한채 길잃은 양처럼 어려움을 겪고 있습니다.
이렇게 연구자들이 선행연구들을 이해하기 어려운 이유 중에 하나는 대학원 과정에서 체계적으로 훈련을 받지 못하였기 때문으로 판단합니다. 특히, 직장인들은 시간 부족으로 인하여 더 불리한 조건에 내몰려 있습니다.
직장과 대학원생활을 겸하고 계시는 분들이 제대로 논문작성법을 안다면, 자신의 직장생활을 통해 얻은 좋은 정보나 통찰력을 바탕으로 좋은 논문을 발표할 수 있는 분들이 의외로 많다는 것을 잘 알고 있습니다. 특수대학원의 설립목적은 바로 이런 분들에게 지식생산방법을 교육하여 양질의 논문을 세상에 내놓게 하는 것이라고 믿습니다.
뿐만 아니라 풀타임 대학원생들도 조금만 더 꼼꼼히 가르치고 지도해드리면 보다 좋은 '지식'들이 생산되어 학계에 주목받을만한 주제가 많다는 것을 경험적으로 잘 알고 있습니다.
이런 분들에게 "논문은 스스로 알아서 쓰는 것"이라는 주장은 가혹하기조차 합니다. 시간과 비용을 들였는데도 논문작성에 기초가 안되어 있다는 것은 우리 사회의 슬픈 현실이기도 합니다.
따라서 '대학원=논문작성법교육=지식생산방법교육기관'이라면 현재와 같이 대학원을 수료한 학생들이 지식펜의 과외지도 없어도 논문작성이 가능하여야 합니다.
그러나 현실은 그렇지 않습니다.
서울시내 모 대학원 졸업생들의 평균 8%정도만 겨우 학위를 받는 것으로 파악되고 있습니다. 이런 현상들은 우리 대학원교육시스템이 원활하게 작동하지 않고 있다는 증거이기도 합니다. 지식펜은 이런 우리사회 대학원의 현실을 '비난'하기 보다 '대안모색'을 실천한 결과라고 감히 주장합니다.
한편, 지난 30여년 동안 우리 사회의 인사청문회 때마다 '논문대필'과 '논문표절' 이슈가 끊이지 않았습니다. 그러나 지식펜이 생기기 이전까지 아무도 이 문제에 대한 해법을 내놓지 않았습니다. 석박사를 마치면 우리 사회의 상당한 지도층일진데 '도덕성 시비'에 내몰려 있는 상황에서 어찌 우리사회의 미래가 밝다고 말할 수 있겠습니까?
대학원 교육시스템이 잘 정비되어 대학원교육이 정상화된다면 지식펜은 없어도 될 것이라는 주장이 가능합니다. 저희는 그렇게 되어도 괜찮다고 믿습니다. 그러나 대학의 교수님들은 자기연구, 강의를 통한 지식전파, 후학지도 외에도 우리사회의 'Think tank'로서 수행해야 할 역할이 너무 많습니다. 이런 이유 등으로 대학교수님들은 몸이 두 개라도 감당하기 힘든 일명, '직무소진' 상태에 놓여 있다고 믿습니다.
따라서 논문지도와 같은 업무를 불법적인 대필이나 대행이 아니라 합법적인 방식으로 외부기관에서 도와드린다면 여러가지 측면에서 긍정적이라고 판단하고 설립된 회사입니다. 즉, 연구윤리도 건강해지고, 대학교수님들의 부담을 덜어드려서 궁극적으로 우리 사회가 대학교수님들의 '지식자원'을 보다 긴급하고 중요한 영역에 사용토록 한다면 더 좋을 것이라는 판단입니다.
저희 지식펜은 이런 문제를 해결하기 위해 합법적 논문컨설팅을 시작하지 9년에 접어든 가장 오래된 역사와 규모를 지닌 대표업체입니다. 저희가 내세우는 중요한 장점 중에 하나는 저희와 함께 일하고 있는 '논문지도박사'들입니다. 지식펜의 논문지도박사님들은 지식생산방법인 '연구방법론'을 충분히 이해하고 계시는 분들이며 학술연구에 상당한 실적을 보유한 분들만 선발되고 있습니다. 불행하게도 실력위주의 인재 선발시스템이 부족한 탓에 상당한 실력을 갖추고도 후학 양성의 기회를 얻지 못한 '박사인재'들이 많다는 것에서 잘 알고 있는 저희 지식펜은 이런 분들에게 좋은 기회를 제공하고 있습니다.
논문지도는 고객님들의 인생에 중요한 영향을 미치는 과정입니다. 따라서 박사학위를 가진자라고 해서 아무나 남의 인생의 중차대한 과정을 함부로 다룰 수 없습니다. 다행히 저희 지식펜은 역사만큼이나 오래된 관리시스템과 훌륭한 선발시스템으로 좋은 인력들이 다수 활동하고 있습니다.
저희 지식펜은 단 1문장도 고객의 논문을 대필하지 않습니다. 논문작성의 원리와 체계를 1:1 멘토링 방식으로 한 문장 한 문장을 같이 읽고 고민해주며 그 대안을 제안해주는 합법적 컨설팅 시스템으로 운영되고 있습니다.
지식펜은 큰 꿈이 있습니다.
우선, 대학시스템의 빈 자리를 보완하고 우리사회의 연구윤리를 더욱 건강하게 만들고 있습니다. 더 나아가 보다 양질의 논문이 나오도록 교육함으로서 아직까지 단 1명도 배출하지 못한 노벨과학상 수상자가 나올 수 있도록 정성과 전문성으로 기여하겠습니다. 감사합니다.
지식펜 대표 박원수 배상
현재 국내 대학원 시스템이 인류 역사상 현존하는 유일무이하고 가장 선진화된 무결점의 시스템은 아니나 국내에서 당분간은 이 시스템이 굴러갈 것이라고 생각되어 현재 대학과 대학원 시스템이라는 테두리안에서 글을 쓰고자 합니다. 그리고 제가 일반대학원을 다녔던터라 특수대학원의 시스템을 정확히 모르는 관계로 일반대학원을 기준으로 말을 하려고 합니다.
※ 본 글을 쓰기전에 박원수대표님께서 작성하신 글 중에 확인하고 갈 부분들이 있어서 먼저 집고 넘어가고자 합니다. 그리고 나오는 내용은 전적으로 저의 사견이니 오해없으시길 바랍니다.
[연구자들이 선행연구들을 이해하기 어려운 이유 중에 하나는 대학원 과정에서 체계적으로 훈련을 받지 못하였기 때문으로 판단합니다.]
선행연구를 이해하기 어려운 이유는 두가지입니다. 흥미 또는 필요가 없거나 공부를 안했거나입니다. 본인이 필요한 연구임에도 이해하기 어렵다고 정체되어 있다는 것을 대학원 과정에서 체계적으로 훈련받지 못했다고 둘러대는 것은 좀 안타깝다고 생각됩니다. 어려운 연구들이 있을 수는 있습니다. 그렇다고 가만히 있지 않습니다. 스스로 돌파구를 찾아냅니다.
[직장인들은 시간 부족으로 인하여 더 불리한 조건에 내몰려 있습니다.]
대학원을 진학할 때는 모두들 나름의 이유와 목적을 가지고 시작하게 됩니다. 직장인이기에 시간이 부족하지만 그것이 불리한 조건이라고 말하기는 어렵습니다. 대학을 졸업하고 대학원에 진학한 학생들은 최상의 조건에서 생활하고 퇴직하고 대학원에 진학하는 분들께는 불리한 면이 없을까요? 직장인이라는 것으로 시간이 부족하고 불리한 조건이라고 말씀하시는것에는 어폐가 있다고 보여집니다.
[서울시내 모 대학원 졸업생들의 평균 8%정도만 겨우 학위를 받는 것으로 파악되고 있습니다.]
특수대학원의 경우 졸업과 학위가 동일한지 아닌지 모르겠으나 일반대학원의 경우 졸업을 하면 학위를 수여받는것으로 알고 있는데 졸업생들의 극히 일부가 학위를 받는 것에 대한 내용은 확인 부탁드립니다.
-본글-
학위를 마무리하는 작업에는 거무튀튀한 라면 받침에 최적화된 하드커버 논문이지만 그 논문을 작성하기 위해서 소위 삽질들을 무수히 하게됩니다.
이 삽질이 보는이에 따라서 무의미하고 시간낭비라고 볼 수 있지만 그 삽질속에서 시행착오를 거치면서 성장 할 수 있는 기반을 다지고 생각하는 힘을 가지게 된다고 생각합니다.
이런 무의하다고하는 과정을 이미 경험했으며 연구방법과 논문 지도에 특화되고 전문화된 분들께서 컨설팅을 해서 이런 소모성 시간을 단축해주겠노라 그리고 글로벌한 수준의 논문을 작성할 수 있게끔 지도해주겠다라고 '지식펜'이라는 컨설팅 기관이 출현했는데 과연 그 무의미하다고 생각되는 단계와 시간을 단축하는 것이 정말 학위하는 과정에 필요한 것인지 혹은 학위 이후에 연구를 해나가는데 있어서 맞는 것인가 하는 것은 다른 이야기라고 봅니다.
이런 논문/연구 컨설팅업체가 필요없다 필요하다는 제가 말할 위치도 아니고 있어서는 안되는 악으로도 보지 않습니다. 시장이 있는데 사업을 하지 않는 것은 말이 안되죠. 다만 이것이 진짜 업체에서 얘기하는 긍정적인 측면이 더 큰지는 잘 모르겠습니다. (컨설팅 업체가 있음으로써 연구 부정/논문 대필이 줄어드는 효과를 보일 것인지는 잘 모르겠습니다.)
그래서 '지식펜' 광고에 실소가 절로 나왔습니다.
안타깝게 주위에 지식펜에 컨설팅을 받아 본 지인이 없는 관계로 무조건적인 비판과 비난은 적절치 않다고 보지만 학위 논문을 작성하기까지 그간 겪었던 것은 학위를 받는 것에 것에 끝나지 않고 스스로 생각해서 연구를 하기 위한 훈련을 하는 것도 포함된다고 생각해서 지식펜이라는 컨설팅에 부정적인 생각이 큰 것 같습니다.
스스로 연구를 진행함에 있어서 습관은 무섭게 작용할 것 입니다. 학위를 하면서 무엇인가 큰 바위로 인해 길이 막혔을 때 손쉽게 해결해 주는 요술 지팡이를 언제든지 쓸 수 있다고 한다면 요술지팡이만을 의지해서 이것이 왜 문제가 있는지 왜 잘못된 방향인지 장고할 시간을 빼앗긴다면 비록 당장에는 시간을 단축했다, 내 열정을 다른 더 좋은 곳에 사용 할 수 있을 것이라 느껴지겠지만 결국 점점 더 의존하게 되는 악순환이 될 수도 있습니다.
적재적소에 지식펜과 같은 컨설팅을 활용한다면 이상적인 교육 생태계가 만들어질수도 있겠지만 과연 이런 적재적소에 기여해서 선순환적인 결과를 만들어낼지 현재의 교육 시스템을 보면 어렵다고 생각됩니다. (이 부분은 교육 컨설팅업체들만의 문제보다는 교육시스템의 문제긴 합니다.)
지금까지 일반대학원을 기준으로 글을 작성하였는데 특수대학원이 기준이 된다면 지식펜과 같은 컨설팅업체가 필요할수도 있겠다 생각이 들었습니다. 특수대학원의 경우 일반대학원과는 달리로 현장 실무를 익힌 분들을 위한 재교육의 목적이 크기에 현장에서 사용되는 보고서나 제안서등에는 탁월할지 모르나 학문을 위한 논문이라는 양식에 대해서는 어려워 할 수도 있고, 비록 위에서는 제가 직장인이라고 해서 불리한 조건이 아니라는 얘기를 했으나 이는 일반대학원의 경우로, 특수대학원을 기준으로는 좀 달라질 수 있다고 보기에 한편으로는 이들을 위해서라면 컨설팅 업체의 존재가 필요 할 수도 있을것 같았습니다.
그러나 위에서 박원수 대표님께서 언급하신 최근 대두되는 고위공무원들의 학위 논문 문제들에 대해서는 업체측의 무던한 노력이 필요할 것 이라고 생각됩니다.
아래는 최근 학위논문으로 문제가 됐던 분들 중 몇 분의 내용을 확인해 본 것입니다.
#이름 (나이) 문제가된 학위논문/ 논문이 문제가된 시점/ 논문 작성 당시 직위 (순서는 나이순)
최흥집 (1951) 1993년 강원대 경영대학원 석사학위 / 2014년 강원도지사출마 /국제관광박람회조직위원회 총괄기획부 부장
박승주 (1952) 2004년 동국대 행정학대학원 박사학위 / 2016년 안전처장관 내정자 / 확인못했음
서남수 (1952) 1995년 동국대 교육대학원 박사학위 / 2014년 교육부장관 /교육인적자원부 기획관리실 교육정책기획관
윤성규 (1956) 2006년 한양대 산업경영대학원 석사학위/ 2013년 환경부장관 후보자 / 제14대 국립환경과학원 원장
이철성 (1958) 2000년 연세대 행정대학원 석사학휘 / 2016년 경찰청장 내정자/ 공무원
조경규 (1959) 1991년 서울대 행정대학원 석사학위 / 2016년 환경장관 내정자 / 29회 행정고시, 공무원
※위의 분들 중 문제가 없었던 분들이 있다면 알려주시기 바랍니다. 수정하도록 하겠습니다.
사측의 무던한 노력이 필요하다고 말한것은 위에서 언급되는 분들은 현재 장관 내정자및 후보자들이며 학위를 받는 때도 이미 조직위원회 총괄 부장 및 정책기획관, 경찰공무원, 국립환경과학원장등 일정 수준의 직책에 있었던 분들이 다수였습니다. 이는 후에 높은 자리에 나아가기 위한 스펙쌓기로 밖에 보이지않고 이런 사람들과 컨설팅업체가 결탁을 하게된다면 이는 위와 같은 고위공무원이 될 사람들의 학위 논문에 문제가 없도록 세탁해주는 하청업체로 밖에 전락하지 말라는 법이 없기 때문입니다.
일반대학원의 기준으로는 과연 이런 업체가 학위자들에게 결과적으로 득이 될 까라는 생각이 컸고, 특수대학원을 기준으로는 도움이 될 수도 있겠지만 이는 연구부정및 논문 문제들과 같은 문제에 대해서는 학위자들과 컨설팅업체의 도덕성에 맡기는 수밖에 없다고 생각됩니다.
사견으로는 좋은 시선으로 보지 않고 있지만 논문 컨설팅의 그 뜻을 끝까지 잘 지키시고 공사다망하시길 바랍니다.
사측의 무던한 노력이 필요하다고 말한것은 위에서 언급되는 분들은 현재 장관 내정자및 후보자들이며 학위를 받는 때도 이미 조직위원회 총괄 부장 및 정책기획관, 경찰공무원, 국립환경과학원장등 일정 수준의 직책에 있었던 분들이 다수였습니다. 이는 후에 높은 자리에 나아가기 위한 스펙쌓기로 밖에 보이지않고 이런 사람들과 컨설팅업체가 결탁을 하게된다면 이는 위와 같은 고위공무원이 될 사람들의 학위 논문에 문제가 없도록 세탁해주는 하청업체로 밖에 전락하지 말라는 법이 없기 때문입니다.
일반대학원의 기준으로는 과연 이런 업체가 학위자들에게 결과적으로 득이 될 까라는 생각이 컸고, 특수대학원을 기준으로는 도움이 될 수도 있겠지만 이는 연구부정및 논문 문제들과 같은 문제에 대해서는 학위자들과 컨설팅업체의 도덕성에 맡기는 수밖에 없다고 생각됩니다.
사견으로는 좋은 시선으로 보지 않고 있지만 논문 컨설팅의 그 뜻을 끝까지 잘 지키시고 공사다망하시길 바랍니다.
월요일, 1월 09, 2017
clustalw 설치
clustalw를 설치하기 위해서는 일단
다운로드를 받아야 하겠죠?
소스파일 clustalw2
프리컴파일 파일 clustalw2-libcppstatic
프리컴파일된 파일을 다운받아서 사용해도 되고
소스 파일을 다운받아서 설치하셔도 됩니다.
$tar zxf clustalw-2.1.tar.gz
$cd clustalw-2.1
$./configure --prefix=/install/path/clustalw-2.1/
$make install
그냥 이렇게 하시면 clustalw가 설치되고 잘 사용하시면되겠습니다. :)
목요일, 12월 29, 2016
SILVAngs
QIIME2이후 새로운 녀석이 나타났다!!
silvangs음.. 왠지
MG-RAST 대항마로 나온듯
MG-RAST야 분석 파이프라인만 제공하는것에 반해
silvangs의 경우 막강한 16S rRNA DB를 탑재하고 있으니...

그리고 silvangs도 일단은 credit으로 운영중 가입하면 300k주고 시작하는데
과금 방법이 분석횟수인지 분석에 필요한 스텝기준인지 아직
안사용해봐서 잘 모르겠다능.. :)
여튼 단점은 rDNA용 커뮤니티 분석이라는것이 한계
WGS가 플랫폼으로 나오면 대박일듯... 물론 WGS이 나오기에는 아직
넘어야할 산이 좀 있으니...
불안불안한 MG-RAST에 이어 web 기반 분석 플랫폼이 나와준것에 박수를..
목요일, 12월 15, 2016
HaploMerger2
HaploMerger2
HaploMerger2 논문
HaploMerger2 다운로드 사이트 , HM2 메뉴얼
2012년 HaploMerger1 개발 이후 2014년에 성능이 향상된 HaploMerger2로 2015년 11월자 파일이 최신인 프로그램으로 간단히 정리하면 polymorphism으로 인해 assembly가 제대로 되지 않는 genome을 assembly하여 고 퀄러티의 genome을 얻는데 도움을 주는 도구 되겠습니다. :)
기본적인 작업 프로세스는 아래의 순서도를 따릅니다.

HM2에서 제공되는 batch 스크립트를 보시면 위에 모식도를 그대로 구현해 놓은것이라고 보시면 됩니다.
HM2 설치는 다른 것들과 달리 컴파일하는거 없고 그냥 다운받아서 압축 파일만 풀면 되는데 run_all.batch파일이 속을 썩일수도 있습니다.
run_all.batch파일안에 치환해야 하는 파일 이름들 중 mp_ref/alt_ss이나 mp_ref/alt_ss_re이 것을
mp_ref_ss와 mp_alt_ss로 분리해주시면 중간에 에러나서 실행되지 않는 step들이 해결될것입니다. 그리고 추가적으로 우리 kent옹께서 만드신 faToNib도 필요하고 여기저기 숨어있는 풀어야할 문제들이 약간씩은 있을 수 있으나 log파일 확인하시면 다 나오는것이니 너무 걱정하지 마시고 일단 run 해보시면됩니다. libraries안에 gapCloser.cfg와 sspace_libraries.list는 GapCloser와 SSPACE할때 필요한 라이브러리 설정 파일입니다. 그 안에 형식에 맞게 fastq파일 넣어주시면됩니다.
마지막으로 HM2가 많이 궁금하신분은 제가 아는 선에는 HM2를 가장 잘 다루는 사람은 (주)테라젠이텍스의 박신기대리님이신듯!! 궁금한것 박대리님께!! 물어보십시요!! ㅋ :)
화요일, 12월 06, 2016
HGAP 버전 비교
PacBio에서 assembly를 담당하고 있는 HGAP과 Falcon을 주로 사용하고 있는것으로 알고 있는데 오늘 그 중에서 HGAP을 잠시 확인 하도록 하겠습니다.
왜 HGAP만 확인하느냐?
제가 HGAP을 많이 쓸 예정이거든요 ㅋ
Falcon궁금하시면 직접 하시면됩니다!! :)
우선 HGAP 버전을 한번 살펴보겠습니다.

HGAP버전을 보시면 3개가 존재합니다. 그러나 HGAPv1의 경우 이미 이번 SMRT버전에서 퇴출당했습니다. 당시에는 long read로 어셈블리해서 획기적으로 계산량을 줄이긴 했으나 Celera Assembler 자체가 시간이 많이 걸리기 때문에 (CA자체라기 보다는 특정 모듈들이겠죠?) 자체 프로그램을 고안해서 HGAPv2외에 추가로 HGAPv3까지 내놓은 상황입니다.
근데 보통 New버전 나오면 예전거 갈아치우는데(한국이 그런 경향이 많긴하지만.. 모 특정 위치에 있는 분들은 상당히 잘 안바뀌긴하죠..) HGAPv2와 HGAPv3를 계속 사용하고 있습니다. 두개의 큰차이는 consensus 부분인데 이것에 따라 속도와 결과물 차이가 나기때문에 두개 결과중에 좋은거 사용해라하는 느낌이 있습니다.
그래서 현재 HGAPv2와 HGAPv3에 대해서 테스트를 계획중이고
각 단계별로 parameter를 바꿔주면 어떻게 바뀌는지 비교해볼 계획입니다.
PacBio를 사용하시는 업자분들께서는 어떤 버전을 최적화해서 사용하는지는 잘 모르겠으나 아마 각각의 장단점이 있을겁니다. 그래서 직접 테스트를 해보겠다능~ :)
그럼 HGAP 비교글은 내년에 좀 더 볼만한 내용을 찾아뵙도록 하겠습니다. :)
getopts.pl 이 없다면!!!
perl script를 실행시킬때 Can't locate getopts.pl 이라는 에러가 났을때
당신의 OS가 우분투라면?
당신의 OS가 우분투라면?
apt-get install libperl4-corelibs-perl로 해결가능합니다. orz
월요일, 12월 05, 2016
16S rRNA와 시퀀싱플랫폼
블로그에 쓰는 내용이 16S rRNA에 많이 집중되고 있긴하죠? ㅎㅎ
하는일이 이거다보니.. :)
여튼 오늘은 16S rRNA와 시퀀싱플랫폼에 대해서 잠시 이야기 하도록 하겠습니다.
최근 16S rRNA sequencing의 최강자 454가 서비스를 bye bye한 관계로
많은 연구자들이 MiSeq체제로 변환하고 있는데 (물론 Ion도 있고, PacBio도 있습니다.)
기존에 454를 사용했을 때와 다른 V region을 사용하고 다소 다른 결과들을 보이는 것들이
있을 것 입니다. 그래서 이리저리 검색하다가 걸린 논문 두 개를 가지고 잠시 얘기해보고자 합니다.
Nucl. Acids Res. (2010) 38 (22): e200.
PeerJ (2016) 4:e1869
논문을 찾아보기 시작한 이유는 454가 막을 내린 후 다른 시퀀싱 플랫폼에서는 왜 다른 region을 target하고 있고 왜 diversity에 차이를 보이는지... (내가 분석을 잘못했나.. ㅎㄷㄷㄷ)
우선 V region, 454는 V1-V2였는데 MiSeq은 V4 region을, Ion은 4개 region? 7개 region? 을 동시에target하고 있다는..
모 논문보면 아시겠지만
2010년 논문은 454 vs MiSeq을 비교했습니다. 두 플랫폼이 차이가 날까? 어떤것이 차이가 날까?
2010년도 논문을 한장 figure 요약하자면 이거죠

상단은 phylum abundance/ 하단은 genus abundance 그리고 좌측에 있는 V4는 이전 연구에서 사용되었던 기준이라고 생각되는 참고용 분포입니다. 실험 결과가 V4 region이 저 분포를 나타내면 실험이 잘됐다고 확인하는 용도로 사용됩니다.
사실 phylum은 크게 차이없죠, 차이가 있기도 쉽지않습니다.
관심사는 genus되겠습니다. 일루미나 데이터의 대부분은 unclassified입니다. 논문에서는 error때문에 이렇게 나왔으니 error좀 낮아지면 일루미나가 output이 많으니 sequence error 문제점을 개선된다면 미생물 분석에 적합한 킹왕짱 시퀀서가 될거라고 하는데 개인적인 생각으로는 sequence error(454가 일루미나가 한테 sequence error ㅋㅋ 좀 웃겼다능..
systematic error는 눈에 안뵈냐라고 한다면 눼눼, 하긴 이 논문이 2010년이란 것을 감안한다면 무리는 아니긴 합니다.)보다는 db선택이 unclassified문제는 보정할 수 있지 않을까 합니다.
그렇다면 이제 16s rRNA 입문한지 얼마안된 님께서 그렇게 느끼는 느낌적인 이유는
무엇인가?
바로 2016년 논문되겠습니다.
2016년 논문은 PacBio로 시퀀싱한 것을 db에 따라 분석 결과가 달라지는냐에 대한 내용으로
다음 한 장으로 요약 할 수 있겠습니다.
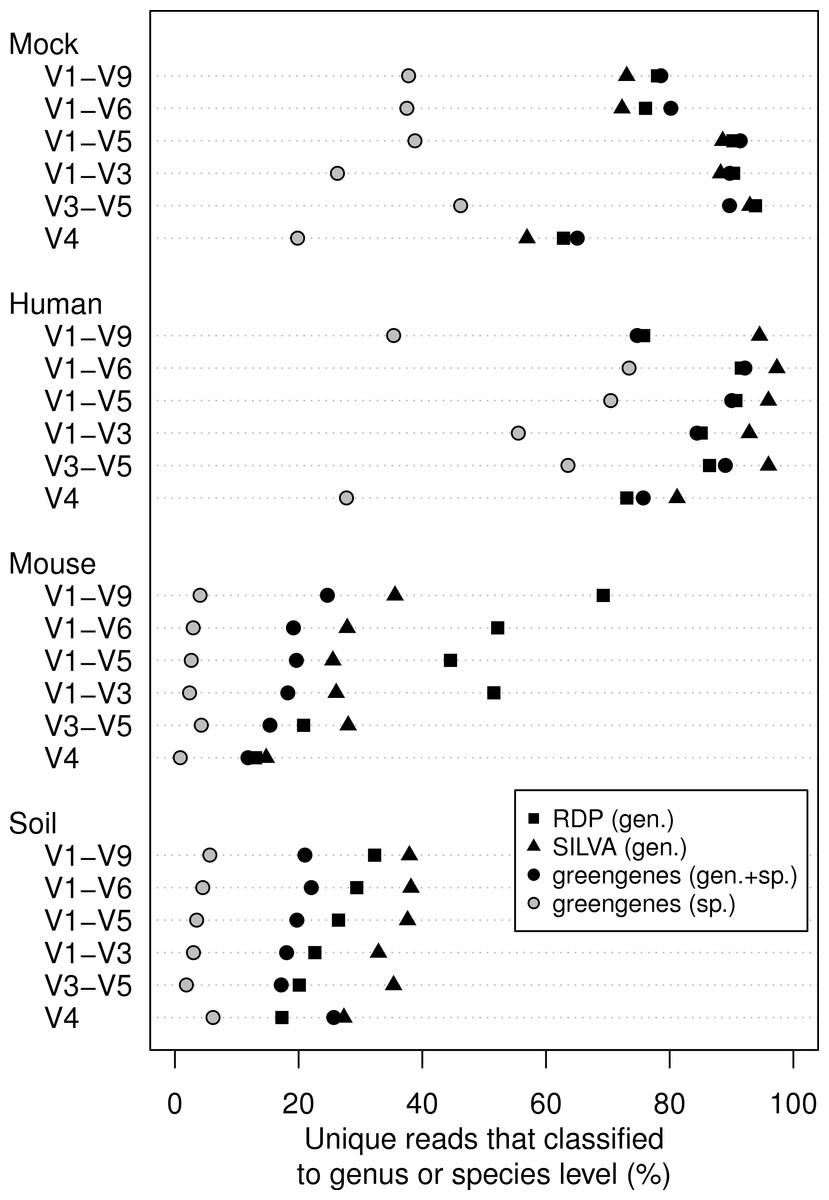
동일한 시료를 가지고 시퀀싱한 데이터를 16S rRNA db에 따라 classification되는 정도를 확인해본 그래프 입니다. 느낌 딹오시죠?
다만 나중에 뒤통수 맞았다는 느낌 안 받게 하나 말씀드리자면 RDP와 Silva의 경우 genus까지만 확인했고 gg는 genus와 genus+species 두가지로 확인한 것 입니다.
이제 PacBio의 Sequel에서 CCS로 생산된 16S rRNA 서열가지고 연구해도 나쁘지 않을 것 같다는..
아.. 이제 돈만 많으면 되는건가!!!
하는일이 이거다보니.. :)
여튼 오늘은 16S rRNA와 시퀀싱플랫폼에 대해서 잠시 이야기 하도록 하겠습니다.
최근 16S rRNA sequencing의 최강자 454가 서비스를 bye bye한 관계로
많은 연구자들이 MiSeq체제로 변환하고 있는데 (물론 Ion도 있고, PacBio도 있습니다.)
기존에 454를 사용했을 때와 다른 V region을 사용하고 다소 다른 결과들을 보이는 것들이
있을 것 입니다. 그래서 이리저리 검색하다가 걸린 논문 두 개를 가지고 잠시 얘기해보고자 합니다.
Nucl. Acids Res. (2010) 38 (22): e200.
PeerJ (2016) 4:e1869
논문을 찾아보기 시작한 이유는 454가 막을 내린 후 다른 시퀀싱 플랫폼에서는 왜 다른 region을 target하고 있고 왜 diversity에 차이를 보이는지... (내가 분석을 잘못했나.. ㅎㄷㄷㄷ)
우선 V region, 454는 V1-V2였는데 MiSeq은 V4 region을, Ion은 4개 region? 7개 region? 을 동시에target하고 있다는..
모 논문보면 아시겠지만
2010년 논문은 454 vs MiSeq을 비교했습니다. 두 플랫폼이 차이가 날까? 어떤것이 차이가 날까?
2010년도 논문을 한장 figure 요약하자면 이거죠

상단은 phylum abundance/ 하단은 genus abundance 그리고 좌측에 있는 V4는 이전 연구에서 사용되었던 기준이라고 생각되는 참고용 분포입니다. 실험 결과가 V4 region이 저 분포를 나타내면 실험이 잘됐다고 확인하는 용도로 사용됩니다.
사실 phylum은 크게 차이없죠, 차이가 있기도 쉽지않습니다.
관심사는 genus되겠습니다. 일루미나 데이터의 대부분은 unclassified입니다. 논문에서는 error때문에 이렇게 나왔으니 error좀 낮아지면 일루미나가 output이 많으니 sequence error 문제점을 개선된다면 미생물 분석에 적합한 킹왕짱 시퀀서가 될거라고 하는데 개인적인 생각으로는 sequence error(454가 일루미나가 한테 sequence error ㅋㅋ 좀 웃겼다능..
systematic error는 눈에 안뵈냐라고 한다면 눼눼, 하긴 이 논문이 2010년이란 것을 감안한다면 무리는 아니긴 합니다.)보다는 db선택이 unclassified문제는 보정할 수 있지 않을까 합니다.
그렇다면 이제 16s rRNA 입문한지 얼마안된 님께서 그렇게 느끼는 느낌적인 이유는
무엇인가?
바로 2016년 논문되겠습니다.
2016년 논문은 PacBio로 시퀀싱한 것을 db에 따라 분석 결과가 달라지는냐에 대한 내용으로
다음 한 장으로 요약 할 수 있겠습니다.
동일한 시료를 가지고 시퀀싱한 데이터를 16S rRNA db에 따라 classification되는 정도를 확인해본 그래프 입니다. 느낌 딹오시죠?
다만 나중에 뒤통수 맞았다는 느낌 안 받게 하나 말씀드리자면 RDP와 Silva의 경우 genus까지만 확인했고 gg는 genus와 genus+species 두가지로 확인한 것 입니다.
이제 PacBio의 Sequel에서 CCS로 생산된 16S rRNA 서열가지고 연구해도 나쁘지 않을 것 같다는..
아.. 이제 돈만 많으면 되는건가!!!
수요일, 11월 30, 2016
MrBayes 설치
MCMC방법으로 Phylogeny Tree를 그려주는 MrBayes!!
(컴파일해서 나오는 실행 파일명이 그닥 맘에 들지 않는 tool중 하나 ㅋㅋ)
자세한건 물어보시지 마시고 요기서는 설치만!
(그렇다고 다음에는 자세한거 말씀드리지는 않는다능)
자 설치를 위해서는 요기에서 말하는 Library는 미리미리 설치하면 암에 안 걸리니 먼저 잘 설치해주시기 바랍니다.
CentOS
Ubuntu
그리고 추가적으로 beagle를 설치하셔야 할겁니다.
Beagle 설치방법은 요기를 참고하시고 대략 밑에처럼 하시면 됩니다.
자세한건 물어보시지 마시고 요기서는 설치만!
(그렇다고 다음에는 자세한거 말씀드리지는 않는다능)
자 설치를 위해서는 요기에서 말하는 Library는 미리미리 설치하면 암에 안 걸리니 먼저 잘 설치해주시기 바랍니다.
CentOS
yum install make,automake,gcc,gcc-c++,kernel-devel,git,autoconf,automake,libtool,subversion,pkgconfig,java-1.6.0-openjdk-devel,openmpi,openmpi-develCentOS에서 Autoconf 버전으로 인해 문제가 발생했을 때는 그냥 컴파일 하세요. :)
$ wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz
$ tar xvfvz autoconf-2.69.tar.gz
$ cd autoconf-2.69
$ ./configure
$ make
$ sudo make install
Ubuntu
apt-get install build-essential,autoconf,automake,libtool,subversion,pkg-config,openjdk-6-jdk,git, openmpi-bin,openmpi-doc,libopenmpi-dev
그리고 추가적으로 beagle를 설치하셔야 할겁니다.
Beagle 설치방법은 요기를 참고하시고 대략 밑에처럼 하시면 됩니다.
git clone --depth=1 https://github.com/beagle-dev/beagle-lib.git
cd beagle-lib
./autogen.sh
./configure --prefix=$HOME
make install
마지막으로
MrBayes 소스파일을 다운로드 받으시고 설치해 주시면 되겠습니다.
MrBayes 소스파일을 다운로드 받으시고 설치해 주시면 되겠습니다.
$ autoconf
$ ./configure --prefix=/install/to/path --enable-mpi=yes
혹은
$ ./configure --prefix=/install/to/path --enable-mpi=yes --with-beagle=/install/to/path
$ make
피드 구독하기:
글 (Atom)