지난번 LGBT그룹에서 성적취향(게이)에 따라 장기기증이 제한된다는 캐나다에서의 일에 관련하여 얘기를 나누다가 머리로만 알고 있다는 것을 깨달아서 글 한편 끄적..
이런 글을 써보는 것이 처음이라 단어들이 어느 한쪽에게는 거북하게 느껴질 수도 상처가 될수 도 있습니다. 읽어보시고 표현이 부적절하다면 대체표현을 제시해주시면 적극 수정하도록 하겠습니다.
세계적으로 국가에서 헌혈을 할 때 불특정다수와 성관계를 맺는 이들과 gay에게 5년 혹은 1년동안 동성혹은 불특정 다수와 성관계를 하지 않은 자에 한해서 허용해주고 있다고 합니다. 이웃나라 중국은 인권관련해서 별 생각없으니 안봐도 알겠고, 미쿡이나 그위에 단풍국마저도 1년정도의 유예기간을 두고 있는 상황입니다(이와 관련된 정리된 표가 있었는데 찾는데로 추가하도록 하겠습니다.). 그리고 국내에서는 저도 작년 10월쯤 헌혈을 했었는데 문진표를 그닥 주의깊게 안봐서 잘 모르겠지만 문진표에 1년이내 불특정 이성과 남성의 경우 다른 남성과 성접촉을 한 것에 대해 묻는 문항이 있다고 합니다.
이 문진표가 왜 문제가 되는것인가?
슬쩍 봤을 때 문제가 진짜 있는거야?라고 생각하실 수 있습니다.
대한민국에 사시는 분들중에 미쿡에서 건너온 자료를
좋아하시는 분들이 있는 관계로 미쿡의 cdc 자료한번 띄어드립니다.
어떠한 사람들이 새롭게 HIV진단을 받는가!
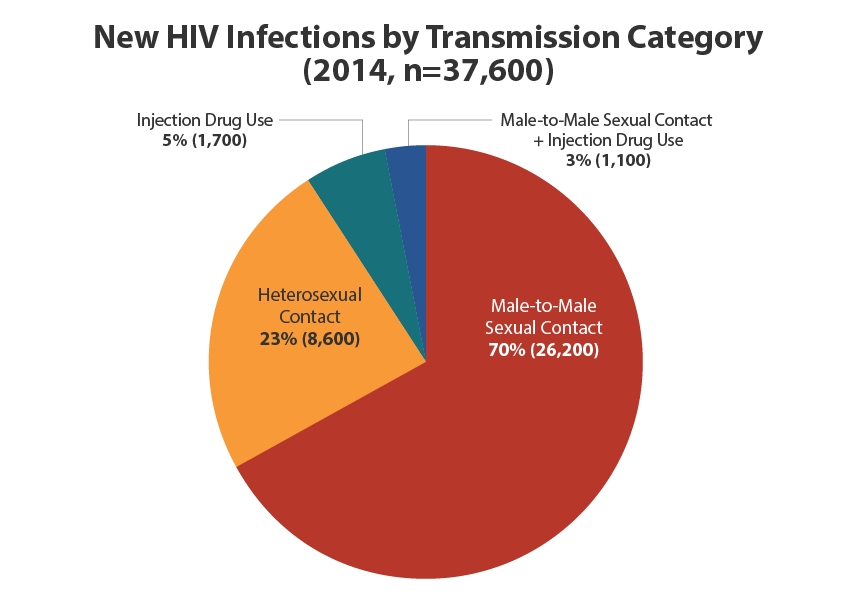
아마 이 그래프 많이 보셨을 겁니다.
이봐 이봐 이래서 gay들은 헌혈 금지해야 한다. 라는 주장에 솔깃 하실겁니다.
이 그래프는 아마도 헌혈 제한에 찬성하는 측에서 옳다구나 사용할만한 그래프라고 생각됩니다.
다음은 위의 그래프와 같은 섹션에 있는 그래프입니다.
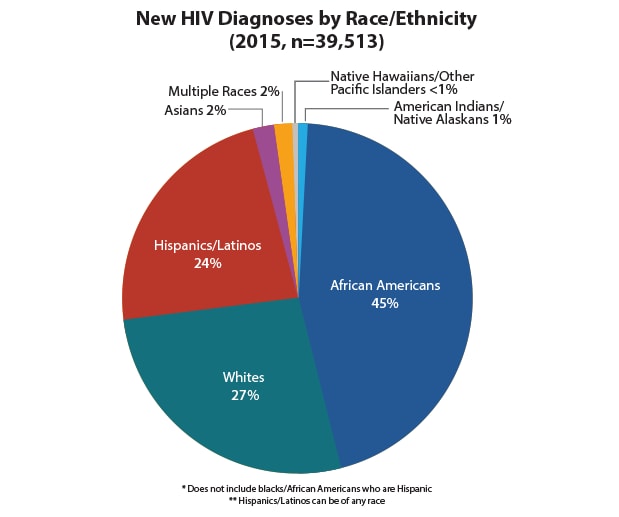
그럼 아프리카계 미국인과 백인들 히스패닉/라틴계 미국인들도 헌혈을 하면 안되는 것인가요?
위의 두 그래프는 HIV관련
CDC 통계 페이지중에서
[How dose HIV affect different groups of people?]섹션에 있는 그래프입니다.
이 그래프들은 단지 HIV에 취약한 그룹들에 대해 얘기하고 있고 그것을 정리한 것입니다.
물론 이 그래프를 보고는 gay에 대핸 헌혈 제한 및 장기기증 제한이 합리적으로 보일 수도 있습니다.
근데 합리적이고 논리적이어야 한다면 이런 성적취향이나 인종적 차이가 아니라 행위에 대해서 제약이 있어야 합니다. (인종에 따라 헌혈을 제한하지는 않지요?)
새롭게 HIV감염자가 된 사람중에 MSM이 67%라서 제한하는것은 합리적이고 이성과 관계한 24%는 안전하기 때문에 제제대상이 되지 않는것이 맞는것일까요?
HIV는 대게 성행위에 의해서 퍼지게 됩니다. 항문이든 질이던간에(드물게 구강성교 또는 HIV환자와 주사기나 기타 장비들을 공유했을때 감염이 될 수 있습니다.) 이건 그냥 제가 아는 상식으로 말씀드리는건 아니고
CDC에서 얘기하고 있습니다. (어디서 사이비지식을 팔고 있냐고 항의하실 분은 이 사이트 어딘가를 찾아보시면 제 연락처가 있으니 연락 주시길 바랍니다. :) ) MSM이라서, 아프리카계 미국인이라서 헌혈과 장기기증에서 제한될 이유는 없는것이죠?
위에서 LGBT그룹의 분들과 대화를 나눌 때 제가 간과하고 있었던 부분이 헌혈시 전수조사로 검사를 하냐 안하냐였습니다.
만약 혈액원에서 전수조사를 하지 않고 문진에 근거해서 선택별 검사를 한다면 저 문진표는 중요할 수 있습니다. 근데 국가 보건과 관련되고 중요한 것인데 이런 문진표에 허위로 기재했다고 법적 처벌 받는 것을 보신적이 있으신지요? 그리고 적십자 홈페이지를 보니 헌혈된 모든 혈액에 대해서 HIV도 전수조사하고 있었습니다. (다만 개별적으로 통보해주는 내역에는 포함되어 있지 않다고 하네요. HIV 검사 목적으로 헌혈을 하는 것을 방지하기 위해서)
이런 상황인데 저 문진표가 소용이 있을까하는 그리고 특정 그룹에 대한 헌혈 제한이 필요한 것인가 라는 궁금증이 드는것이 이상한것이고 이런 생각이 국민 보건에 크게 위협이 되는건지..
HIV 무섭습니다. HIV의 경우 잠복기라는 것이 길어 조기에 잘 확인이 안되는 문제도 있습니다. 그러나 현재 기술로 11일 즉 감염이 됐다면 넉넉히 2주 지나면 확인이 가능합니다.
만약 HIV가 진짜 걱정돼서 문진표에 질문을 꼭 넣고 싶다면 지금의 질문 대신에
"2주안에 안전하지 않은 성관계를 했습니까?"라는 질문으로 혹은 다른 질문으로 대체하는 것이 그렇게 국민 보건 정책에 위반되는 것인지 궁금하다능
제가 성소수자들의 인권에 관심이 많아서 쓴 건 아니고, 제가 잘나서 쓴것도 아닙니다.
제가 머리로만 알고 있는 것과 이런 것을 생활에 녹일때 잘못된 두려움과 편견이 얼마나 빠르게 사실과 이성을 흐릴 수 있는지 기억하고자 쓴 글입니다.








